The breadth of Big Data and Analytics technical architecture can seem intimidating. Despite its diversity, though, it solves a handful of problems. It makes trade-offs and surprise, just moves work around to meet its performance goals.
I’ll attempt to describe the key problems and the tradeoffs simply. These basics should help demystify architecture selection and troubleshooting for technology leaders new to the space.
Big Data is well, big. Too big for one machine to process quickly and store reliably. So, we need a lot of machines, working in parallel, and will have to coordinate their activity. How many? In the extreme, thousands.
Data may stream in so fast that it is hard to even ingest it without falling behind. With so much distributed data, finding and reading it quickly becomes a problem. Finally, reliable storage requires multiple copies and reliable coordination requires a way to handle coordinator failure.
In short, the problems are to:
1. Scale write, read, and processing performance
2. Parallelize work across nodes, i.e., machines.
3. Efficiently share data and coordinate activity across nodes.
4. Reliably process and store data despite one or more node failures.
5. Meet your business needs for data consistency and availability.
Problem 1: Scale write, read, and processing performance.
Writing
At scale, simple things like reading and writing become hard. The physical world is unforgiving, so learn your constraints. You can’t have it all. Ultra fast writes typically means slower reads and vice versa. When you can solve for both, accept that you’ll create a new problem. There are no free lunches at scale.
In a nutshell, store your data in ways that make it easy to do what you need to do with it. And address the consequences. Let’s look at some examples.
A traditional transactional database needs data consistency, so its relational model limits data redundancy. It needs reasonably fast reads and writes, so it defers some of its disc housekeeping, index and other storage optimization to off hours. Just don’t forget to schedule it!
Specifically, most Relational Databases record where they store their data on disc in real time using B+ Trees. Each file write causes multiple updates to the B+ Tree and takes time. To avoid more delay, it writes data somewhat haphazardly to disc blocks, slowing reads. The deferred work moves to clean up jobs.
What if we need faster writes? Well, something has to give. Cassandra, for example, provides faster writes, strong read times, and lightweight transactions. The cost is more data redundancy and less consistency. You also have to agree to less flexible read options — sorts move from query parameter to design decision. But wow, very fast.
To do this, Cassandra, and others, e.g. Kafka, use a Log Structured Merge Tree. Writes are batched based on available RAM (memtables) and appended to a log (SSTables). Deletes and modifications are appended to the log rather than applied to the underlying data store. A compaction process handles data storage changes and optimizations, again in batches.

Source: Creative Coder
These are two common options. There are other optimization strategies that trade off various constraints.
Reading
Let’s stick with the familiar. A traditional relational database, Oracle, SQL Server, DB2, is row oriented, i.e., stores rows together in files on a drive. Rows offer a good fit for transactional use cases, lots of fine grained, surgical inserts, modifications, etc., and AVRO is a common file format. However, analytical use-cases frequently aggregate one column of data from thousands of rows and thus must read more than they need.
The heuristic is to store data the way you want to use it. Analytical use cases benefit from column oriented file structures, like Parquet. They read only what they need to and, given their columns, have homogenous data; so they compress to save storage space.
As always, there is a tradeoff: writes are slower. In fancy language, these structures are great for write once read many workloads. Column database examples, Redshift and HBASE.

Source: datacadamia.com
Yes, there are hybrids. Cassandra and BigTable can save a set of columns (a family), whose data is frequently used together.
You may also optimize for data access granularity. If you need to process large grained objects (files) one by one, then an object storage solution like AWSs S3 fits the bill. It uses a key-value pair where the value is the object, e.g. BLOB, Json file, etc. If you need fine grain access to groups of structured data elements, then consider a low-latency, high consistency, key-value/document database solution like AWSs DyanmoDB.
Note the storage types below. It fits this discussion well, but I’ll hand wave it and just provide a link so if you don’t already know, you can learn more about them.

Source: Cloudain.com
Problem 2: Parallelize work across nodes, i.e., machines.
Since one machine, node, can’t do the work quickly enough, we must parallelize it. We need to abstract away the complexity of dealing with all the different nodes so the developer can focus on the business problem. Map Reduce is one such solution. How it abstracts away the complexity we’ll ignore and simply look at its workflow, which is basic.
Map Reduce does something simple. It collects some data and maps it into a structure, say sales for the week. And then reduces it into something useful, say the min, max, and average sale volumes for the week. The developer writes the logic for the job and the Map Reduce application finds the nodes with the data and runs the logic on each machine in parallel, and then stores it.

Source: Hadoop In Practice
While good for simple tasks, the Map Reduce framework causes a developer to create a lot of jobs and knit them together. Imagine quarter-end reporting as a long list of jobs. At Big Data scale, that is difficult to manage. As we’ll see, this is a solved problem.
Big Data Analytics require complex online analytical processing requires inner joins, outer joins, etc. Frameworks like Tez, HIVE abstract away that NoSQL/SQL complexity using algorithms expressed and coordinated via Directed Acyclic Graphs (DAGs). These graphs flow work from left to right and do not loop.

Source: Medium
DAGs are expressive and easy to use and have become a de facto developer standard for expressing simple and complex workflows, i.e., they are not just powering low level frameworks. Examples include Spark, Beam, Airflow, Kubeflow, and ML pipelines…
ML uses interesting graphs. Feed-forward Neural Networks traverse a graph in one direction, have layers, and evaluate loss at the points where layer nodes meet. Convolutional Neural Networks, and others, use bi-directional traversal, to enable Gradient Descent and Backpropagation.

Source: Brilliant.org
Problem 3: Efficiently share data and coordinate activity across many nodes.
Many machines working in parallel mean many logical and physical boundaries to cross, process, user space, system space, network, and storage mediums, etc. Given speed is a goal, boundaries are a toll, they take time to cross.
Process as much data locally as is practical, I.e. minimize the amount of data passed across the network, processes, or storage boundaries on a node to reduce latency. As mentioned earlier, Map Reduce handles some of this heavy lifting. However, remember it passes data across jobs by persisting it.
As an example, in the Hadoop ecosystem, YARN applications may keep nodes (VMs) active across jobs to keep data in memory for a subsequent workflow step and to avoid VM startup times. The tradeoff is inactive VMs consume memory and may starve others. And there are other examples, Spark uses Resilient Distributed Datasets (RDDs) as a form of shared memory.

Source: tutorialspoint.com
Stating the obvious in distributed systems, avoid workflows that allow hosts to block each other’s tasks, and prefer asynchronous vs synchronous cross node communication. Onto coordination.
Coordination
Coordination happens at multiple levels. We'll keep it simple. Let’s define “coordinate” to mean managing work across nodes. The next section will address failures.
Continuing to use the Hadoop example, let’s look at the “abstracted complexity” that allows developers to not worry about work distribution. There are three layers:
1. YARN (Yet Another Resource Manager) - yep, manages applications, handles some scheduling.
2. MapReduce - organizes where mapper and reducer work will happen (runs in YARN as of Hadoop 2).
3. HDFS - Hadoop Distributed File System - determines where data goes where it is.

Source: Hadoop In Practice
The above diagram highlights a common coordination model, master/slave, or leader/follower, if you prefer. Here, the leader is the authoritative source of what data is “correct” and which node should do what and when. Leader/follower relies on an primary/backup data replication model. A set of changes comes in, let’s say to add a value, and then update it three times. The leader will apply those changes and send the final value to its followers. This can create a single point of failure, so often a backup master who is aware of all the changes. As long as both of them don’t fail at once, all is well. Over two masters? Then there are some overlaps with peer-to-peer.
In centralized distributed computing, leader/follower and peer-to-peer are the main options.
In peer-to-peer, any node can be a leader or a follower; all nodes have the same capabilities and their function, leader or follower, is context dependent. Here, the data replication model is state machine based. While there is a leader, it shares all incoming changes with the other nodes in its cluster so that anyone of them can become the leader if the current leader fails. 
Source: The Log: What every software engineer should know
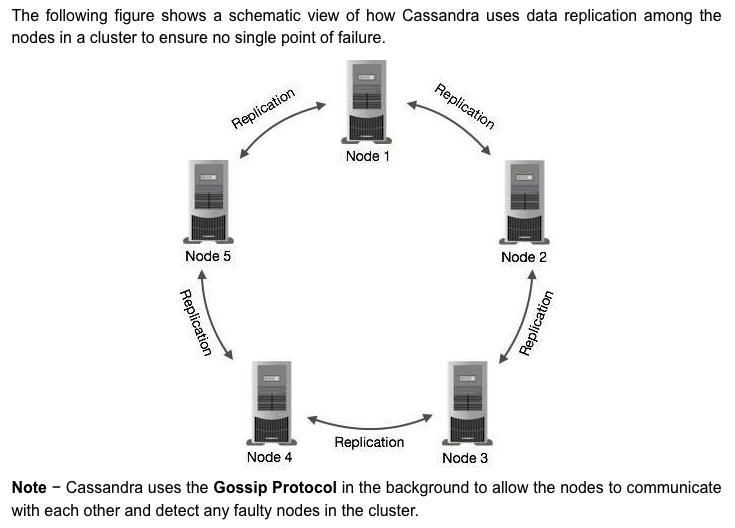
Source: Tutorialspoint.com
Cassandra uses a peer-to-peer model in a ring topology for replication. Its distribution model is blissfully simple, racks and data-centers. Automated replication across data centers is a popular feature. To be nerdy, very cool.

Source: Intstacluster.com
Your work load should drive your choice. Leader follower is simpler, is easier when strict consistency is required, and with back-up masters is reliable. However, with enough inbound requests, it may bottleneck.
Peer to peer is more complex, is chatty (i.e. requires more internode communication), and prefers eventual consistency. However, this complexity provides dramatic horizontal scalability. For example, a Cassndra deployment ran12,000 commodity servers across many data centers/regions. When deployed properly, you won’t get diminishing returns, it scales linearly.
Problem 4: Reliably process and store data despite one or more node failures.
At scale we coordinate 100s to 1000s of nodes and serve 1,000,000s of customer. Some of them, hopefully only the nodes, will fail, and sometimes many nodes will fail together. So peers, followers, and leaders all need to share or replicate their data to at least one partner, and frequently 3 to 5 partners. This data might be a customer order or the identity of the current leader on the network when one has failed.
Regardless of the distribution style, node failure in an asynchronous system introduces a hard constraint - it is not possible to be 100% available and provide 100% data consistency. Yes, those are strong words. Read the FLP proof here.
Given three or more copies of every piece of data, that data values change, and that we can’t instantaneously update all nodes, which nodes have the correct value? And what happens when a node fails? Did only it have the correct value? How would you know? Again, we’ll keep it simple here by discussing only a common conceptual approach, the Paxos algorithm.
The problem is achieving consensus about the correct value of a piece of data at a particular time across multiple nodes when one node can fail. Thankfully, the terminology is straightforward: the nodes must come to a consensus on the correct value, say the value of items in a shopping cart, or perhaps the identity of the current leader.
The lowly log, append only, is often at the center of achieving consensus during replication in this asynchronous world. It has a lot to do with the order in which things happen. But we’ll leave that for another day.
The Paxos algorithm in the abstract is simple. Each participant is a node. A node proposes that the other nodes promise to consider a new value for a shared data element. If a quorum of other nodes promise to consider accepting a new value, then the proposer sends out that value. If a quorum of nodes accepts the new value, then the proposer tells all the nodes to commit the value. And how does each node decide? Well, Paxos is a paper unto itself, so read about it here.
Cassandra, S3s indexing solution, and many others use Paxos. Other solutions, like Zookeepers atomic messaging, used by Kafka, Hadoop, etc. exist as well.
Problem 5: Meet your business needs for data consistency and availability.
The CAP Theorem is important to understand when talking about distributed systems. It is often misunderstood. CAP stands for Consistency, Availability, and Partitioning. Think of partitioning as a failure, a failure of either a node or a network connection.
The point of the Theorem is that, since we can’t avoid node failure (partitioning) in a distributed system, we must optimize for either consistency or availability. The key word is “optimize.” An AP system can be consistent through failures, but it may take longer than your customer can accept.
CP System - prioritizes consistency over availability/speed, i.e., I’m willing to wait because I need the most current data
AP System - prioritizes availability/speed over consistency, i.e., I’m not willing to wait. Give me what you have now. I’ll deal with it.
If you must guarantee consistency and Availability AP, then don’t use a distributed system as it may fail, but it can remain consistent.

Source: Medium